为什么要写这个工具
当MySQL出现性能问题时,DBA经常得去innodb status ,
但是innodb status的输出信息非常丰富也很复杂。滚了几个屏幕的指标,像这样的得翻好几页,几百行的结果。
- 哪些是重要的指标
- 指标具体代表什么意思
- 指标的值是否正常
非常考验DBA的眼力。
考虑到以上的不方便,写了个小脚本把这些指标提取出来,并将指标对应的中文意思和合理取值范围做了详细的备注。
实现思路
- 当用户选中MySQL实例,并点击show engine innnodb statutus按钮时
- 后台进程去该实例执行
show engine innnodb statutus语句 - 返回结果做正则筛选,将各种指标和值保存在一个字典中
- 提前准备好一个指标的字典,字典里记了该值的中文说明和取值范围(取值范围这个还没做好)
- 两个字典一合并,输出一个分好类的可视化结果
指标提取和定义
脚本内容是定义了一个数据字典去翻译这些指标
{
"background_thread":("后台进程:除掉用户请求的活动会话,MySQL后台进程也会定时的进行一系列工作。",[("master_thread_loops_active","","not count","<b>后台master线程avtive执行次数合计值</b>,后台master线程的每次循环时会选择一种状态来执行(active、shutdown、idle),active次数/idle次数 比值越高,代表系统的写操作越繁忙。"),
("master_thread_loops_idle","","not count","<b>后台master线程idle执行次数合计值</b>,和上一个指标连起来看,idle次数越高,代表系统的写操作越少。所以该指标值越大,系统写资源越充足"),
("master_thread_log_flush_and_writes","Bytes","not count","<b>后台master线程刷新redo日志</b>,定期刷新redo日志,和参数innodb_flush_log_at_timeout控制刷新时间")
]
)
,"bufferpool_memory":("缓冲池:有关已读和已写页面的统计信息。可以从这些数字中获得缓冲池的使用情况。",[
("total_large_memory_allocated","Bytes","not count","<b>分配给InnoDB Buffer Pool的总内存</b>")
,("dictionary_memory_allocated","Bytes","not count","<b>分配给InnoDB数据字典的内存</b>")
,("buffer_pool_size"," ","not count","<b>分配给IBP的内存,单位pages</b>,每页16k")
,("buffer_pool_hit","/1000","not count","<b>Buffer Pool命中率</b>每1000次请求有*次命中buffer pool,非常重要")
,("free_buffers"," ","not count","<b>Buffer Pool Free List 总大小,单位pages</b>")
,("database_pages"," ","not count","<b>Buffer Pool LRU List 总大小,单位pages</b>")
,("old_database_pages"," ","not count","<b>Buffer Pool old LRU 总大小,单位pages(冷端)</b>")
,("modified_db_pages"," ","not count","<b>Buffer Pool中脏页的数量,单位pages</b>")
,("pending_reads"," ","not count","<b>等待读入Buffer Pool的页数量,单位pages</b>,理论上不应该有等待队列")
,("pending_writes_lru"," ","not count","<b>LRU中buffer中等待被刷的脏页数,单位pages</b>")
,("pending_writes_flush_list"," ","not count","<b>在checkpoint期间要刷新的缓冲池页数</b>")
,("pending_writes_single_page"," ","not count","<b>在缓冲池中写入挂起的独立页的数目</b>")
,("pages_made_young"," ","not count","<b>热点页数</b>,在缓冲池LRU list中年轻的总页数(移动新页面到sublist的头部)")
,("pages_made_not_young"," ","not count","<b>old sublist中的page数,冷端的page数</b>,在缓冲池LRU列表中不年轻的页面总数(保留旧页面在sublist中,不改变)")
,("pages_made_young_per_sec","page/s","not count","<b>每秒LRU链中被young的page数</b>,oungs/s度量标准仅用于old pages,基于对page的访问次数,而不是页的数量。对页进行多次访问都会被计算。如果见到非常低的值,可能需要减小延迟或增加old page LRU list 的比例。增大后,页面需要更长的时间才会移动到尾部,这就增加了再次访问page,从而使他们made young的可能性增大")
,("pages_made_non_young_per_sec","page/s","not count","<b>每秒LRU链中未被young的page数</b>,可以一定程度上看出库的繁忙程度和命中率,Not young,如果在执行大表扫描时未看到较高的non-young和non-youngs/s,请增加innodb_old_blocks_time。")
,("pages_read"," ","not count","<b>从bufferpool中读取的page总数</b>")
,("pages_created"," ","not count","<b>在bufferpool中创建的page数</b>")
,("pages_written"," ","not count","<b>从bufferpool写入的page数</b>")
,("pages_read_per_sec"," ","not count","<b>从bufferpool中读取的page数/秒</b>, 比较重要,代表库的繁忙程度")
,("pages_created_per_sec"," ","not count","<b>在bufferpool中创建的page数/秒</b>")
,("pages_written_per_sec"," ","not count","<b>从bufferpool写入的page数/秒</b>")
,("pages_read_ahead","page/s","not count","<b>每秒平均预读操作次数</b>k")
,("evicted_without_access","page/s","not count","<b>每秒驱逐的page数</b>k")
,("random_read_ahead","page/s","not count","<b>每秒钟随机预读操作的次数</b>")
,("lrn_len"," ","not count","<b>LRU的长度</b>")
]
)
....此处省略代码若干行
}
实现效果:
用户:输入指定MySQL的ip 和端口,点innodb status 会自动带出一份翻译和标识好的innodb status。
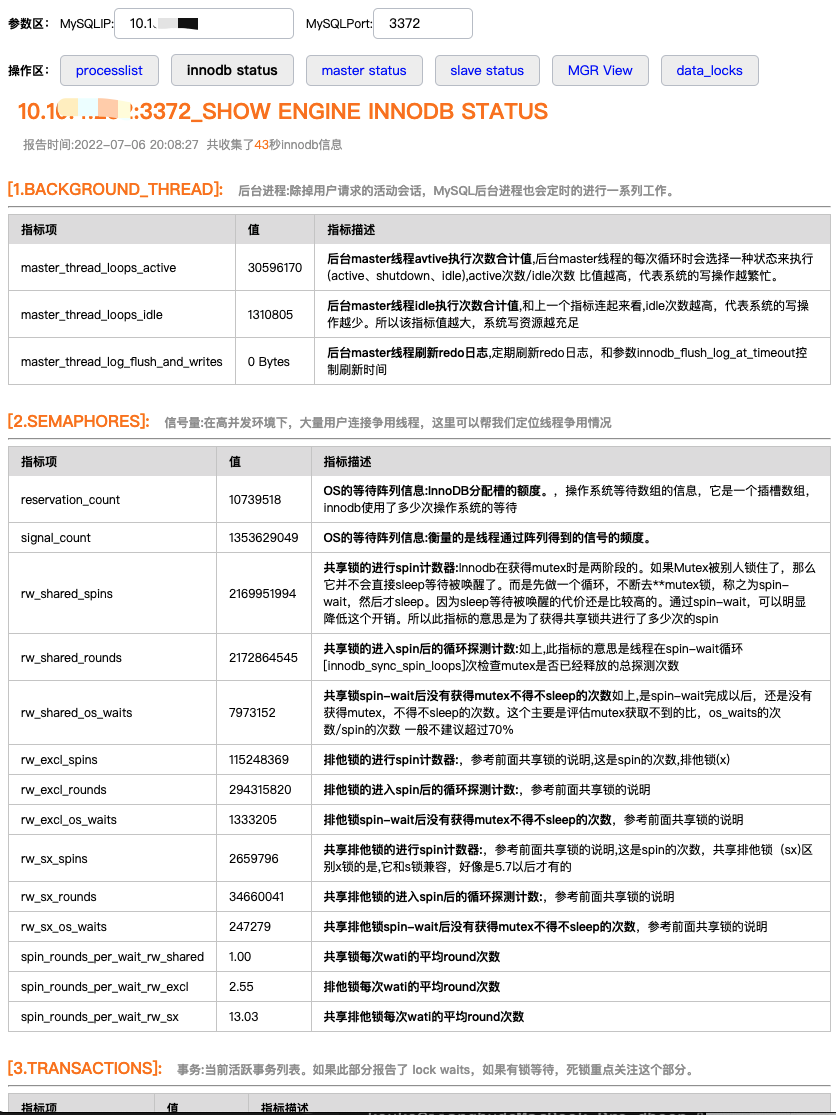
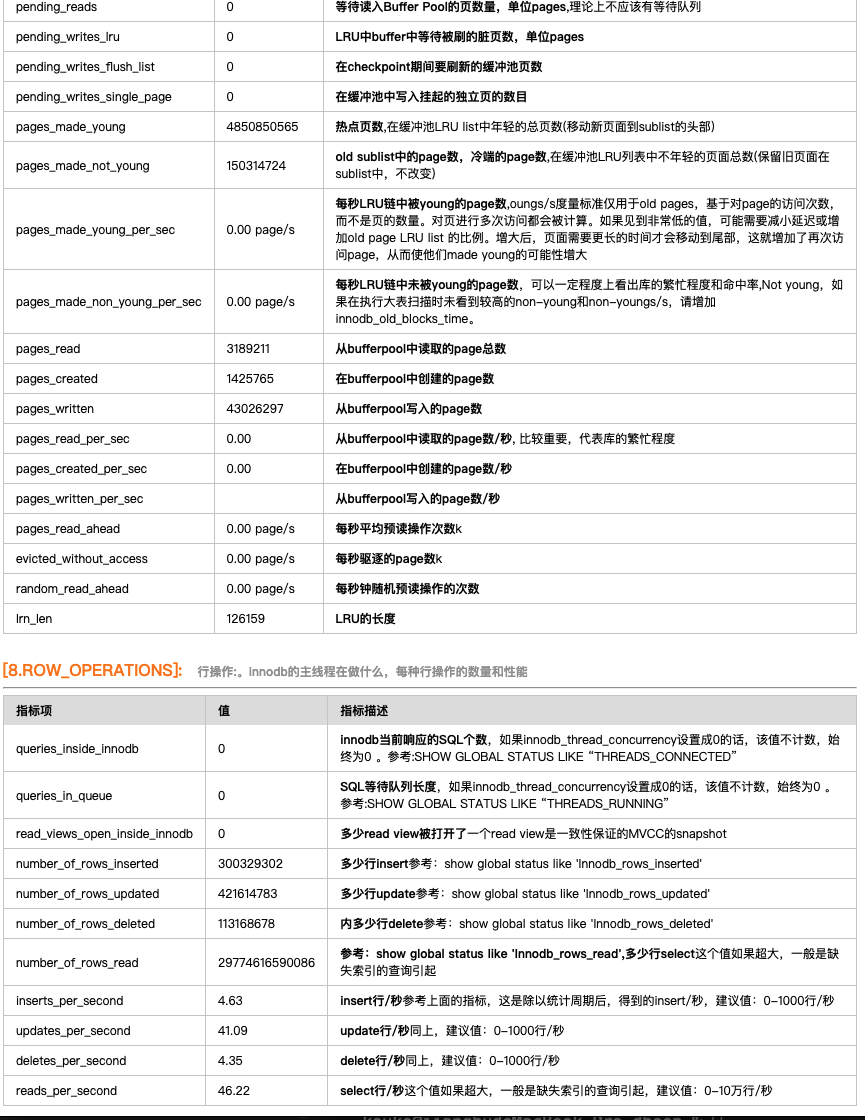
非常nice!
>> Home